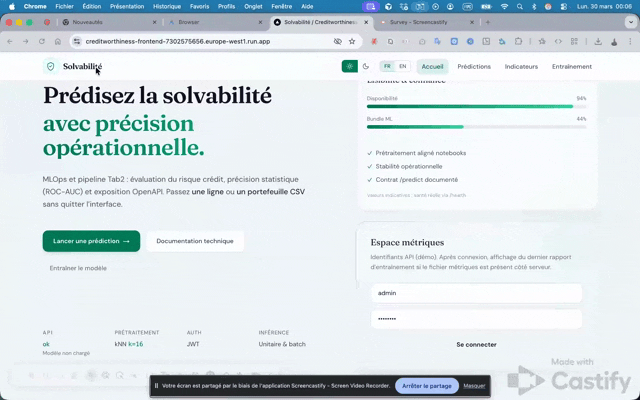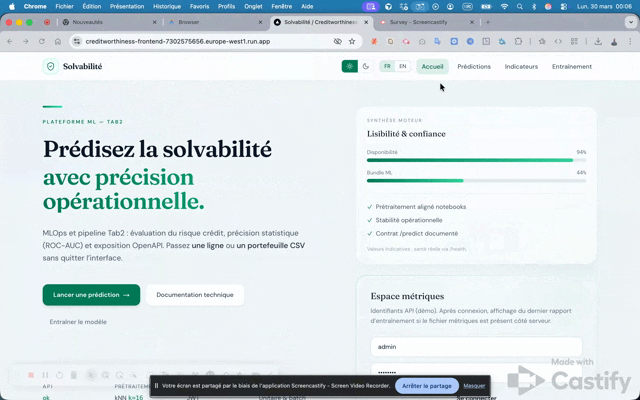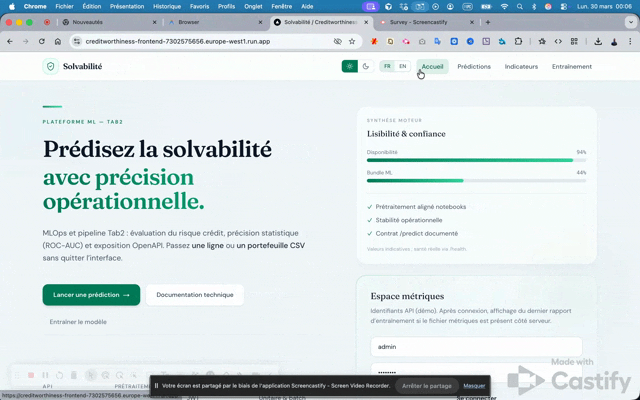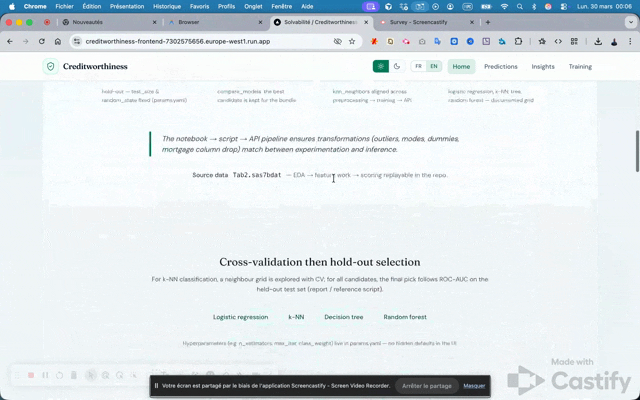
Ce tableau résume des différences de nature (lisibilité, coût, robustesse), pas les scores du dernier entraînement. Il complète le lexique ci-dessus sans dupliquer le tableau de bord Indicateurs.
Historiquement, ranaviz.R et le rapport PDF présentent les trois modèles avec matrices de confusion et taux d’erreur (Decision Tree, Logistic Reg, Random Forest). Le pipeline Python reprend cette même liste de candidats dans params.yaml.
Quand privilégier la régression logistique ?
Lorsque vous devez expliquer clairement le score (coefficients, sens des variables), pour un déploiement léger, ou lorsque la relation cible–features est globalement additive après préparation.
Quand privilégier l’arbre ?
Pour des audits « règle par règle », des ateliers métier, ou un premier modèle très lisible — en acceptant de surveiller la profondeur pour éviter le sur-apprentissage.
Quand privilégier la forêt aléatoire ?
Lorsque la priorité est la performance discriminante sur données riches et bruitées, et que l’interprétation peut passer par l’importance des variables plutôt que par une seule règle.
Les indicateurs chiffrés (ROC-AUC, F1, répartition des classes) du modèle chargé après entraînement se trouvent sur la page Données projet